What is DVC?
DVC (data version control) is an open source tool for tracking datasets and outputs of Data Science and Machine Learning projects.

DVC is designed to be integrated into your Git workflows. On top of that, the interface of DVC is very similar to Git's, so if you are familiar with Git you will find starting to use DVC very easy.
So why should you start using DVC if you already have Git to track code and an a Azure instance to store your datasets and models?
- DVC integrates seamlessly with both Git and all major storage systems (AWS, Azure, Google Cloud, HTTP, SSH server, HDFS, ...) and does not require installing and maintaining any databases.
- DVC makes your projects and all their related data reproducible and shareable, allowing to answer questions on how a model or a result was obtained.
- DVC lets you treat complex Data Science pipelines as a Makefile, so that when something changes (e.g. a new training dataset, a new choice of model hyperparameters, ...) each stage of the pipeline is automatically re-run whenever needed.
Getting Started
DVC is available on PyPI and it is very easy to install:
pip install dvc$ pip install dvc[s3] # support Amazon S3
$ pip install dvc[ssh] # support ssh
$ pip install dvc[all] # all supportsTo use DVC you should work inside of a Git repo. If it does not exist yet, we create and initialize one.
$ mkdir ml_project & cd ml_project
$ git init
$ dvc init
$ git status -s
A .dvc/.gitignore
A .dvc/config
A .dvc/plots/confusion.json
A .dvc/plots/default.json
A .dvc/plots/scatter.json
A .dvc/plots/smooth.json
A .dvcignore
$ git commit -m "Initialize dvc project"
Data Versioning
Let us assume that in our ML project we have 200,000 images that we want to use to train and test a
classification model able to distinguish dogs from cats.
data
├── train
│ ├── dogs # 95,000 pictures
│ └── cats # 95,000 pictures
└── validation
├── dogs # 5,000 pictures
└── cats # 5,000 pictures
$ dvc add data/
100% Add|██████████|1/1 [00:30, 30.51s/file]
To track the changes with git, run:
git add .gitignore data.dvc
$ git add .gitignore data.dvc
$ git commit -m "Add first version of data/"
$ git tag -a "v1.0" -m "data v1.0, 200,000 images"
As you can see, if you are familiar with Git, the syntax of DVC looks straightforward.
But what exactly has happened when we executed
dvc add data/? Actually, quite a lot of things!
- The hash of the content of
data/was computed and added to a new data.dvc file DVC updates.gitignoreto tell Git not to track the content ofdata/. - The physical content of
data/—i.e. the 200,000 images— has been moved to a cache (by default the cache is located under.dvc/cache/). - The files were linked back to the workspace so that it looks like nothing happened (the user can configure the link type to use: hard link, soft link, reflink, copy).
Now, what happens when you modify some DVC-tracked data? Let us assume for instance, that you
replaced some images in data/train/ with higher definition ones, or that you added new
training images to data/train/. We can easily check what has changed with dvc
diff:
$ dvc diff
Modified:
data/
dvc add
, so that DVC will re-compute the hash of data/ to know which version of your repo
corresponds to which contents.
$ dvc add data/
$ git diff data.dvc
outs:
-- md5: b8f4d5a78e55e88906d5f4aeaf43802e.dir
+- md5: 21060888834f7220846d1c6f6c04e649.dir
path: data
$ git commit -am "Add images + Improve quality in data/train/"
$ git tag -a "v2.0" -m "data v2.0, 300,000 images in HD"
data/, we can easily switch from one
version to another using Git and DVC.

- First, we run
git checkoutto switch to a specific revision of the project. This will guarantee thatdata.dvccontains the hash of the correct version the dataset we are interested in, but this command does not modify the files in the workspace, i.e. the content ofdata/.$ git checkout v1.0 $ dvc diff Modified: data/ - Second, we fix the mismatch between the hash written in
data.dvcand the hash of the content ofdata/by runningdvc checkout. This command fetches from the DVC cache the correct version of the dataset based on the hash found in thedata.dvcfile.$ dvc checkout M data/ $ dvc status Data and pipelines are up to date.
Working with Storages
A remote storage is for dvc, what a GitHub is for Git.
- It is used to push and pull files from your workspace to the remote.
- It allows easy sharing between developers.
- It provides a safe backup in case of catastrofic deletions (like
rm -rf *).
$ mkdir -p ~/tmp/dvc_storage
$ dvc remote add --default loc_remote ~/tmp/dvc_storage
Setting 'loc_remote' as a default remote.
$ git add .dvc/config # DVC wrote here remote storage config
$ git commit -m "Configure remote storage loc_remote"dvc push, DVC will upload the content of the cache to the remote storage.
This is pretty much like a git push.
$ dvc push
300000 files pusheddvc pull. Again, this is pretty much like git pull.
$ rm -rf .dvc/cache data
$ dvc pull # update .dvc/cache with contents from remote
300000 files fetched
$ dvc checkout # update workspace, linking data from .dvc/cache
A data/Machine Learning Pipelines
So far we have seen how dvc add can be used to track large files or datasets. When we
work on Machine Learning projects, trained models are typical examples of large files we would like
to track.
However, we also want to track how such models (as well as other outputs of our ML pipeline) were generated, for reproducibility and better tracking. Let us consider the following example of a Machine Learning pipeline for a NLP (Natural Language Processing) project of sentiment analysis.
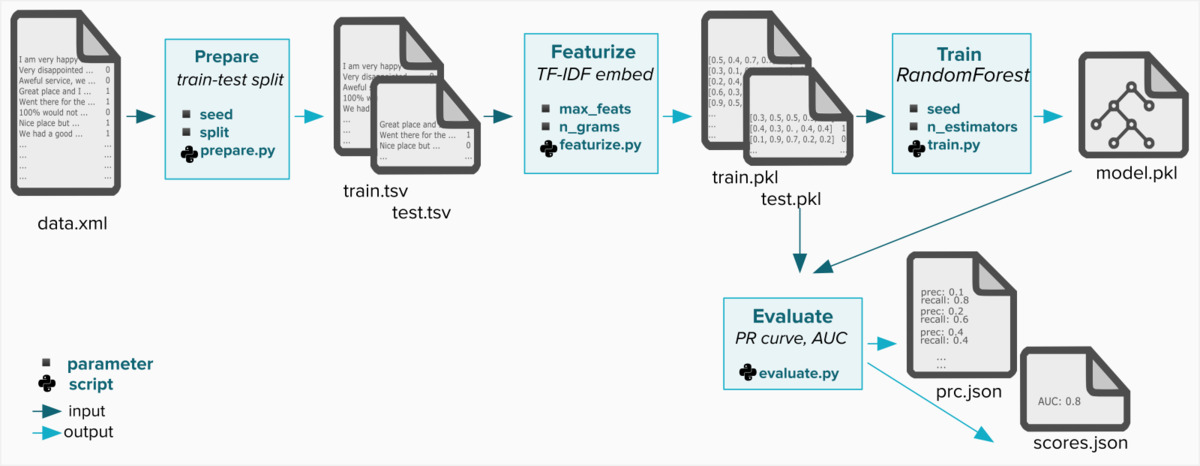
To track each stage of this pipeline with DVC, we can run the pipeline stage and track its output
together with all the dependencies with dvc run:
$ dvc run -n prepare \ # name of the stage
-p prepare.seed \ # dependency (parameter)
-p prepare.split \ # dependency (parameter)
-d src/prepare.py \ # dependency (file)
-d data/data.xml \ # dependency (file)
-o data/prepared \ # output
python src/prepare.py data/data.xml # command to runparams.yaml file that could look
like this:
prepare:
split: 0.20
seed: 20170428
featurize:
max_feats: 500
ngrams: 1
...There are several advantages of using this dvc run approach instead of running the pipeline
stages, and then tracking the output artifacts with dvc add.
- Outputs are automatically tracked (i.e. saved in
.dvc/cache). - Pipeline stages with parameters names are saved in a
dvc.yamlfile. - Dependency files and parameters as well as outputs are all hashed and tracked in a
dvc.lockfile. - The file
dvc.yamlworks as aMakefile, in the sense that we can reproduce each stage of the pipeline withdvc repro prepare, which automatically decides to re-run each stage only if one of the dependencies has changed.
dvc.yaml, which as said describes the graph structure of the data
pipeline,
similar to how
a Makefile works for building software.
stages:
prepare:
cmd: python src/prepare.py data/data.xml
deps:
- data/data.xml
- src/prepare.py
params:
- prepare.seed
- prepare.split
outs:
- data/prepareddvc.lock generated by dvc run , it is a bit like the *
.dvc files generated by dvc add.
In particular, code.lock matches dvc.lock and describes latest pipeline state
in order to:
- track intermediate and final artifacts (like a
*.dvcfile) - allow DVC to detect when stage defs or dependencies changed, to trigger re-run when
dvc reprois called.
prepare:
cmd: python src/prepare.py data/data.xml
deps:
- path: data/data.xml
md5: a304afb96060aad90176268345e10355
- path: src/prepare.py
md5: 285af85d794bb57e5d09ace7209f3519
params:
params.yaml:
prepare.seed: 20170428
prepare.split: 0.2
outs:
- params: data/prepared
md5: 20b786b6e6f80e2b3fcf17827ad18597.dirIf dvc.yaml is like a Makefile, running dvc repro is similar to
running the make command. Once we have run all stages of the pipeline, if we change one
of the
dependencies and run dvc repro train, only the affected stages will be re-run.
$ sed -i -e "s@max_features: 500@max_features: 1500@g" params.yaml
$ dvc repro train
'data/data.xml.dvc' didn't change, skipping
Stage 'prepare' didn't change, skipping
Running stage 'featurize' with command:
python src/featurization.py data/prepared data/features
Updating lock file 'dvc.lock'
Running stage 'train' with command:
python src/train.py data/features model.pkl
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lockFinally, a useful feature of DVC pipelines is that it easily allow to compare parameters and scores of models corresponding to different versions.
$ dvc params diff
Path Param Old New
params.yaml featurize.max_features 500 1500
$ dvc metrics diff
Path Metric Value Change
scores.json auc 0.61314 0.07139Conclusions
- DVC is a simple yet powerful version control system for large ML data and artifacts.
- DVC integrates with Git through
*.dvcanddvc.lockfiles, to version files and pipelines, respectively. - To track raw ML data files, use
dvc add— e.g. for input dataset. - To track intermediate or final results of a ML pipeline, use
dvc run— e.g. for model weights, dataset. - To easily compare parameters and results of two versions of a pipeline, use
dvc params diffanddvc metrics diff, respectively.